

Ollama is an open-source platform that allows you to run open-source large language models (LLMs) locally on your system.
What is Ollama API?
Ollama API is an open-source platform that allows users to run large language models locally on their systems. It allows users to use the REST API to generate responses.
In this article, I am going to share how you can use the REST API that Ollama provides us to run and generate responses from large language models (LLMs). I will also show how you can use Python to programmatically generate responses from Ollama.
3 Steps to Use Ollama to Run LLMs
- Ollama API is hosted on localhost at port 11434. You can go to the localhost to check if Ollama is running or not.
- We will use
curlin our terminal to send a request to the API.curl https://localhost:11434/api/generate -d '{ "model": "llama2-uncensored", "prompt": "What is water made of?" }'
Here, I am using the llama2-uncensored model, but you can use any available models that you downloaded through Ollama. We can also send more parameters such as stream, which when set to false will only return a single JSON object as a response.
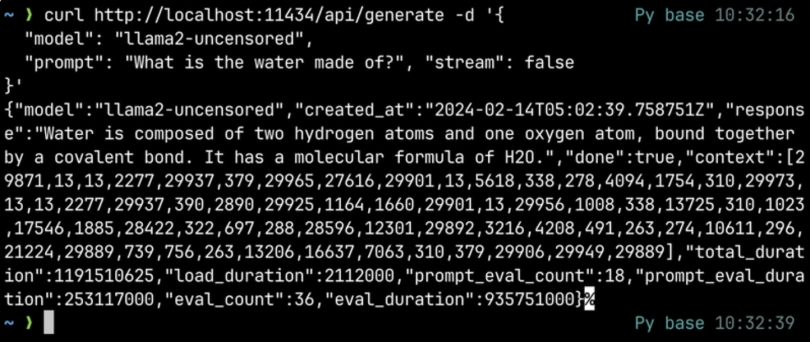
- Now, as we see, the
/api/generateendpoint is used to generate a response/completion for a given prompt. There are various endpoints that we can use for different purposes. You can check them out at the API Documentation of Ollama.
How to Generate Responses Through Ollama API Using Python
Now, we can use Python to generate responses programmatically.
- Create a Python file. Import requests and json library.
import requests import json - Create the URL, headers and data variables with values like the image below:
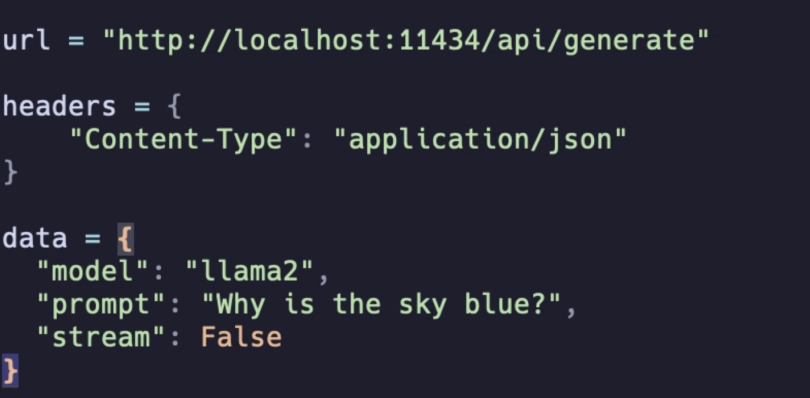
Creating the URL, headers and data variables. | Screenshot: Jayanta Adhikary - Now, use the post method of the response library and pass in the URL, headers and data variables that we created above. Store the response in a variable:
response = requests.post(url, headers=headers, data=json.dumps(data)) - Now, check the status code of the response. If it is 200, print the response text, else print the error. We can extract the exact response text from the JSON object like the snapshot below.

Extracting a response from the JSON object. | Screenshot: Jayanta Adhikary - Run the program.
The complete snapshot of the code should look like this:
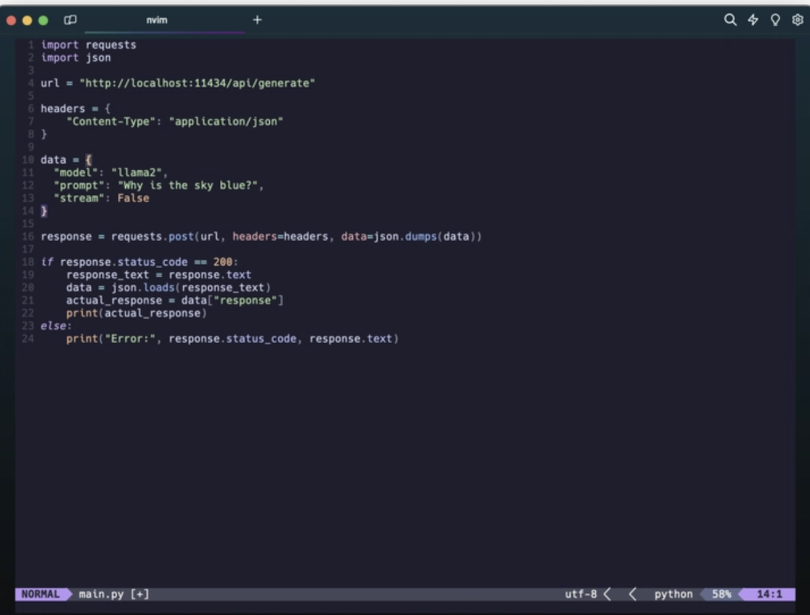
By following the steps above you will be able to run LLMs and generate responses locally using Ollama via its REST API. You can now use Python to generate responses from LLMs programmatically.
Frequently Asked Questions
What is Ollama API?
Ollama API is an open-source platform that allows users to run large language models locally on their systems. It is hosted on localhost at port 11434.
How do you use Ollama API to run LLMs?
- Check the localhost to determine if Ollama is running.
- Use curl in your terminal to send a request to the API:
curl https://localhost:11434/api/generate -d '{ "model": "llama2-uncensored", "prompt": "What is water made of?" }' - The /api/generate endpoint is used to generate a response.


